Privacy Evaluation with Adversarial Learning
This study investigates why the privacy evaluation behaves erratically when a same-gender target selection algorithm is used, and improves its robustness with a larger recognizer and adversarial learning.
Links
- GitHub repository - the results can be found as a release
- Paper (accepted to ICASSP 2026)
Problem
To anonymize an utterance, we have to replace the identity of the source speaker with another one, called the target speaker. How to select these target speakers has been investigated often, because researchers saw that they can have a big effect on the outcome of the privacy evaluation. When evaluating private kNN-VC, we saw a similar phenomenon: for the same-gender target selection algorithm (TSA), which selects a target speaker randomly among those that have the same gender as the source speaker, the equal error rate (EER, the privacy evaluation’s metric) was much higher than for the completely random TSA. This meant that the privacy estimates for the same-gender TSA were larger, although the anonymizer is the same, which does not make sense. An ablation showed that the privacy evaluation yielded large privacy estimates because the TSA was divided into two, regardless of their gender. As we expect the privacy estimates to be the same regardless of the TSA, because the anonymizer does not change, this behavior is a bug of the privacy evaluation.
Experiments
We run three experiments. The first one shows that using a larger recognizer solves the privacy estimation issues posed by the same-gender TSA. For the evaluation of private kNN-VC, we had used the VPC 2024 evaluation. Here we show that increasing the size of the speaker recognizer to match the one provided by Speechbrain solves the privacy overestimation for same-gender TSA: the EERs are no longer 50\%. In fact, the EERs for same-gender TSA are lower than for the random TSA, as we expect given that preserving gender gives away the source speaker’s gender.
Our second experiment consists of adding a target classifier to the speaker recognizer during training, to see how useful the recognizer’s representations are for identifying target speakers. Assuming imperfect anonymization, the anonymized utterances should encode information about both the source and the target speakers. We therefore expect both to be identifiable. Surprisingly, the results show that the recognizer encodes more information about targets than sources, even though we are not propagating the gradients from the target classifier back to the speaker recognizer. Private kNN-VC is a strong anonymizer, resulting in speech where speaker information comes predominantly from the target speaker, but that is not the speaker we are interested in, nor the one we are optimizing for.
To steer the recognizer towards the source speaker, for the third experiment we propagate the target classifier’s gradients back to the recognizer adversarially. The results show that adversarial learning removes target information from the recognizer, improving the evaluation’s outcome for same-gender TSA. We also run this experiment for ASR-BN, with similar results, and for kNN-VC, for which it is not as effective, but because kNN-VC is not confused by targets in the first place, as shown by the validation error rate on the target speakers.
Speaker-level TSA
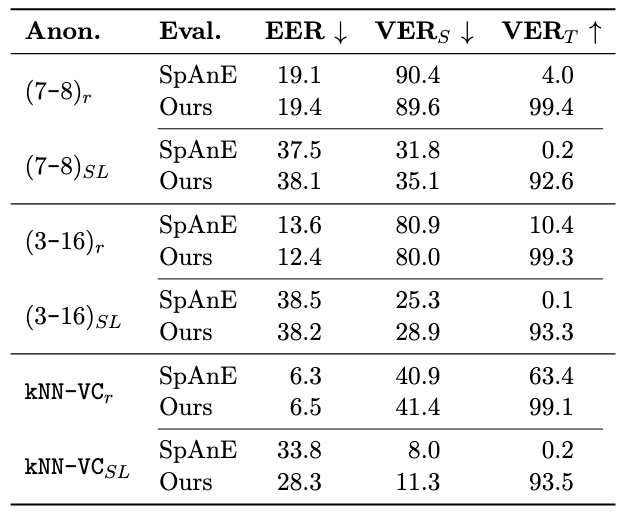
Since submitting the paper, I ran an additional experiment with the speaker-level TSA. This TSA is more challenging than the same-gender TSA, because the link between sources and targets is stronger (Panariello et al). For the same-gender TSA, each source’s utterances were anonymized with different targets; for the speaker-level TSA, they are all anonymized with the same target. The recognizer can improve its identification accuracy on the seen speakers of the training set much more when considering the targets selected by the speaker-level TSA. Our approach with adversarial learning is not able to force the recognizer to ignore targets, as you can see in the table below. Only for the weaker anonymizers (kNN-VC and to a lesser degree the (3-16) config of private kNN-VC) does adversarial learning improve the EER. The error rates for the target speakers are still much higher with adversarial learning, but they do not translate in better EERs, highlighting one of the main challenges of adversarial learning: the recognizer is trying to fool the target classifier, while still leveraging target information to identify the source speakers. Increasing the size and weight of the target classifier, to make it more foolproof, does not solve this issue. The mutual information between the two tasks is too strong; an adversarial approach is not enough to discourage the recognizer from exploiting the TSA.
Conclusion
New approaches are required to improve the evaluation’s robustness to the TSA. For example, training the recognizer on an open-set setting, where there is no fixed number of speakers, could prevent it from leveraging the TSA for identifying training speakers. Self-supervised approaches like contrastive learning or self-distillation could be interesting in this regard.
Until these are developed, adversarial learning is effective for certain TSAs. You can run the target classifier in SpAnE, either only for analysis or with adversarial learning.